Bedömning av uppfyllelse av miljökvalitetsnormer och relation till gränsvärden
Indikatorer
Data i form av mätvärden kan användas för att skatta parametrar för en målpopulation.
Detta är ofta tillräckligt vid monitoring, där syftet är att följa en utveckling för att kunna slå larm om något parametervärde uppvisar en negativ trend. I många andra sammanhang, t.ex. enligt EU-direktiv (t.ex. Vatten, Habitat) eller våra svenska miljömål ska direkta beslut tas rörande uppfyllelsen av ett givet mål.
För att utifrån data kunna avgöra om ett mål ska anses vara uppfyllt har de ”egentliga”, kvalitativa, målen översatts till kvantitativa storheter och formulerats operativt i form av indikatorer. Så ingår t.ex. ”volymen död ved per hektar” som en indikator på det svenska miljömålet ”levande skogar”. Varje mål omfattas i regel av ett antal indikatorer och det är deras värden som helt eller delvis avgör om målet är uppfyllt eller ej. Nedan diskuteras frågan om hur beslut kan tas utifrån indikatorernas värden och vilka problem som det möter.
En ganska generell målformulering
Låt oss beteckna det sanna värdet av en indikator med Y. En enkel och tämligen generell målformulering för den indikatorn är då
där G är ett givet gränsvärde, alltså ”värdet av Y är minst lika med G” (eller ”högst lika med”).
Några exempel för att belysa detta:
Ex. 1. Volymen död ved per hektar (Y) i viss typ av skog ska vara minst 4.8 m3sk (G).
Ex. 2. Förbuskningen (i täckningsgrad) ska minska med minst 10 % till år 2020 i visst habitat. Om vi har täckningen Y1 idag och Y2 år 2010 så ska tydligen gälla att Y2 ska vara högst 0.9⋅Y1. Om vi därför väljer indikatorn Y=Y2 - Y1 så blir målet Y ≤ 0.
Ex. 3. En viss indikator på vattenkvalitet gav klassen ”God” år 2010. Kvaliteten ska då även år 2020 (som ett exempel) inte vara sämre, vilket innebär att indikatorns värde Y år 2020 måste vara minst lika med undre gränsen G för klassen, d.v.s. Y ≥ G.
Ex. 4. Man har under en längre tid observerat att en indikators värde avtar linjärt (mot något icke önskvärt) och därför insatt åtgärder. Som mål har man satt upp att ”trenden ska brytas till det bättre”. Betecknar vi riktningskoefficienten (lutningen) med Y1 före åtgärd och Y2 efter så är målet att Y=Y2-Y1 inte ska vara negativ, alltså att Y≥0. Förmodligen skulle man här välja målet Y ≥ G, där G är en positiv konstant som anger den positiva skillnaden mellan trenderna.
Även om formuleringen (1) kanske inte täcker alla fall så är det en lättbegriplig utgångspunkt för fortsättningen.
Uttrycket (1) uttrycker ibland inte ett direkt mål, utan är en klassificeringsregel. Populationen klassificeras till en klass om (1) är uppfyllt, annars till en annan.
Data, skattning, osäkerhet
Vi vet inte värdet på Y, utan det måste skattas ur data. Skattningen betecknas 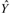 nedan. Man eftersträvar att skattningen inte är behäftat med systematiskt fel och att den är så noggrann som möjligt givet de resurser vi har för datainsamlingen. Precisionen anges i skattningens standardavvikelse (vi antar då avsaknad av systematiskt fel), som ofta kan skattas (approximativt eller nästan exakt), med medelfelet SE(). Långtifrån alltid är skattningen ett medelvärde (eller en skillnad mellan två) och då kan medelfelet vara komplicerat men det påverkar inte framställningen här.
nedan. Man eftersträvar att skattningen inte är behäftat med systematiskt fel och att den är så noggrann som möjligt givet de resurser vi har för datainsamlingen. Precisionen anges i skattningens standardavvikelse (vi antar då avsaknad av systematiskt fel), som ofta kan skattas (approximativt eller nästan exakt), med medelfelet SE(). Långtifrån alltid är skattningen ett medelvärde (eller en skillnad mellan två) och då kan medelfelet vara komplicerat men det påverkar inte framställningen här.
Metoder för bedömning av måluppfyllelsen
Det finns minst två metoder i omlopp för bedömning om målet (1) är uppfyllt, nämligen
Dessutom kan det vara intressant med multipla mål. Det kan också vara relevant att använda hjälpinformation, från datainsamlingen eller genom statistiska modeller, för att minska osäkerheten i skattningarna.
Program
Det finns ett program, WISERBUGS (extern länk), med vars hjälp man med simuleringar kan göra beräkningar av risken för felklassificering. Det är utvecklat för det system som används av Vattendirektivet, med fem klasser och alltså fyra klassgränser (av typ G i den generella målformuleringen ovan). Man specificera en viss statistisk modell, med flera slumpmässiga faktorer och ett antaget sant Y, varefter programmet genom simulering (upprepade lottningar av värdena på slumpmässiga faktorer) skattar sannolikheten att man hamnar i fel klass. Vid multipla mål ska man ansätta en vägd målvariabel (se Multipla mål). Programmet kan alltså ge viss erfarenhet (”känsla”) för risken att felklassificera, men man kan inte direkt använda det för bestämning av risken i ett enskilt faktiskt fall. Programmet kan laddas hem utan kostnad.
