Att analysera flera variabler samtidigt - En introduktion till multivariata metoder
Beskrivning
Detta är en typ av analyser som i många delar skiljer sig från mer traditionella statistiska tester. Själva begreppet multivariat analys syftar på den typ av data som används i dessa tekniker. Inom multivariat analys finns en mängd olika analysmetoder. Dessa kan delas in i två huvudtyper, ordination och klassifikation. Ordination är en form av sortering av prover och klassifikation delar in prover i grupper. Båda metoderna bygger på olika matematiska sätt att beskriva hur mycket de insamlade proverna liknar varandra.Vi börjar med att ställa frågan: - Vad är multivariata data?
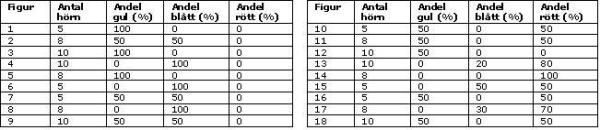
Multivariata data har man när man har flera studerade objekt (t.ex. sjöar, provytor, nederbördsprover) som är beskrivna med flera variabler, eller karaktärer. Vattenprov kan t.ex. vara beskrivet eller karaktäriserat av kanske 20 olika kemiska variabler. Provytor för vegetation beskrivs av de arter som finns i ytorna. Som en illustration av ett multivariat dataset finns nedan 18 figurer som är beskrivna av fyra karaktärer: antal hörn, andel gult, andel blått och andel rött. I tabellen under finns dessa karaktärer kvantifierade.

Inom miljöövervakningen är de enskilda proverna att jämföra med de olika figurerna i exemplet ovan. De variabler man mäter, räknar eller observerar på varje prov motsvarar de fyra karaktärer som beskriver figurerna.
Vilka frågor kan man då svara på med hjälp av multivariat analys?
Multivariat analys kan sägas vara olika former av avancerad sortering och klassifikation. Objekt som liknar varandra kommer att hamna nära varandra medan objekt som är mer olika i de beskrivningskaraktärer man använt kommer att hamna längre ifrån varandra. Detta kan man utnyttja för att:
- hitta gradienter i ett stort datamaterial,
- gruppera objekt efter hur de liknar varandra,
- undersöka vilka variabler som är de styrande för att beskriva variationen i ett dataset,
- skapa hypoteser, och
- testa hypoteser.
Exempel
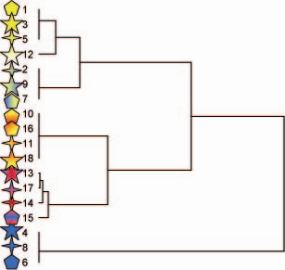
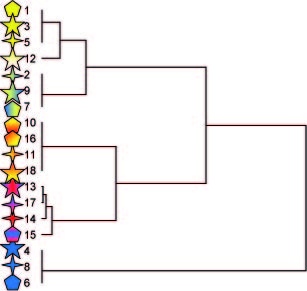
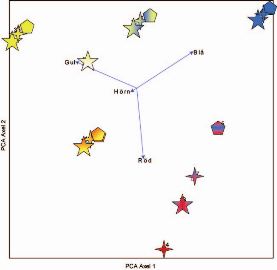
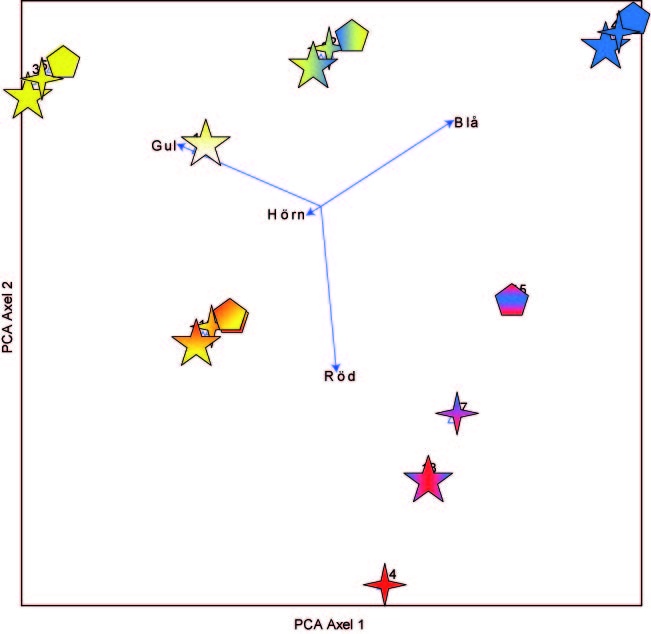
Multivariat analys kan ske med båda huvudtyperna av multivariata analyser, ordination och klassifikation. I figuren nedan är en ordination presenterad till höger och en klassifikation till vänster. I ordinationsdiagrammet bildar axlarna gradienter som separerar objekten efter inbördes likheter och olikheter. I detta fall är figurerna separerade efter andel gul färg längs den horisontella axeln, och efter en röd-blå gradient längs den vertikala axeln. Vi kan också få fram att antalet hörn är av underordnad betydelse när det gäller likheter och olikheter mellan figurerna, medan andelen olika färger är ungefär lika viktig för alla tre.Figuren till vänster visar en klassifikation av de 18 symbolerna. Den vanligaste typen av klassifikationer är så kallad dikoton delning, dvs. alla objekt delas in i två grupper. Därefter delas dessa grupper ånyo in i två grupper, och så vidare. I vårt exempel bildas en första skiljelinje mellan de helblåa figurerna och resten. Därefter delas övriga figurer in i allt finare grupper. Den andra delningen skiljer ut alla figurer som har någon andel röd färg från de utan röd färg.
Indirekta ordinationsmetoder – PCA, (D)CA och NMDS
Indirekta ordinationsmetoder (PCA, (D)CA och NMDS) extraherar och sammanfattar variationen i ett multivariat dataset, och uttrycker variationen längs ordinationsaxlar, eller komponenter. Den starkaste gradienten i ett dataset visas längs den första ordinationsaxeln eller komponenten. Om man råkar ha starkt avvikande värden är oftast den starkaste gradienten den mellan avvikaren och övriga värden. Beroende på frågeställning och anledning till att värden avviker kan man välja att ha med eller ta bort avvikarna i fortsatta analyser (se figuren nedan). Observera att avvikande värden eller prover inte behöver var felaktiga, men att man ändå kan välja att ta bort dem för att studera övriga prover.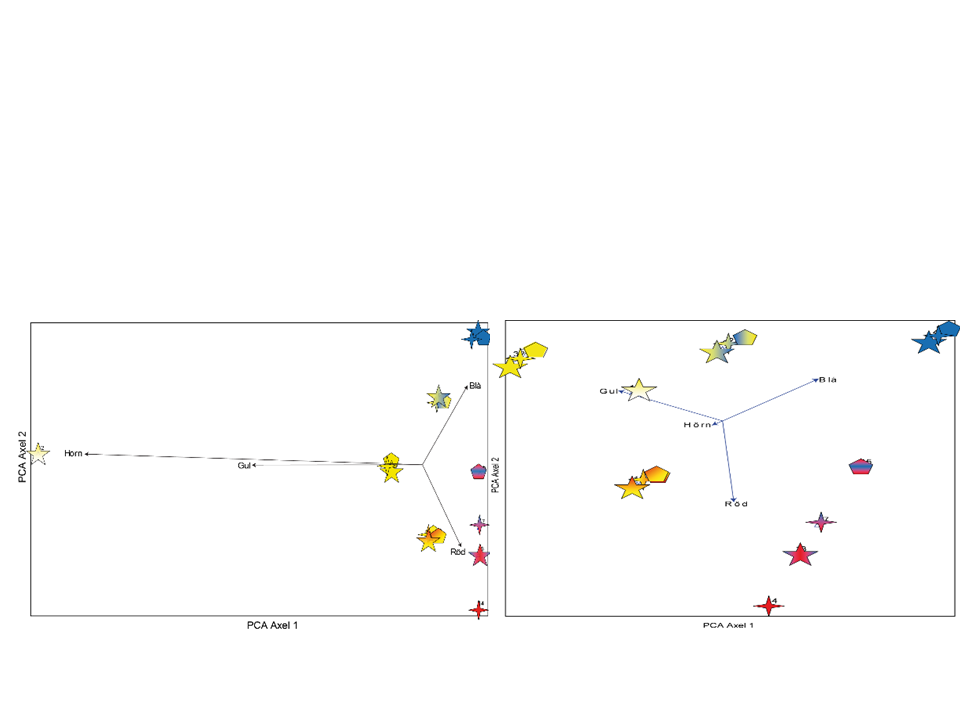
Illustration av hur ett avvikande värde skapar den starkaste gradienten (axel 1) i en ordination. Till vänster har ett objekt råkat få 100 gånger för högt värde för variabeln ”Hörn”, till höger samma data men med det avvikande värdet korrigerat. Ovanstående exempel illustrerar hur en ordination fungerar. I beräkningarna extraheras den starkaste gradienten i et dataset, och uttrycks längs den första (horisontella) axeln eller ”komponenten” med annan nomenklatur. I indirekta metoder (som PCA, (D)CA och NMDS) får man i efterhand tolka vad det är som ligger bakom den funna gradienten. I direkta metoder tar man med förklaringsvariabler i beräkningarna redan från början, därav namnet ”direkta”.
Viktigt att veta
Det finns en hel rad olika multivariata metoder. Vilken metod som skall användas beror på vilken typ av data och vilka frågeställningar man har. Här finns ett flödesschema för guidning till rätt multivariat metod.Det kanske viktigaste är att veta vilken typ av teoretisk fördelning som beskrivningsvariablerna följer. I princip räcker det med att veta på om man analyserar kemiska variabler eller organismer. Om objekten (proverna) är beskrivna av vilka organismer (växter eller djur) som finns i varje prov, följer beskrivningsvariablernas fördelning den biologiska nischteorin. Denna säger att organismer har en Gauss-formad fördelning längs alla tänkbara miljögradienter. Detta innebär att en viss organism har ett optimum vid vissa miljöbetingelser, och att den minskar i förekomst ju längre från detta optimum man kommer (högra figuren nedan).
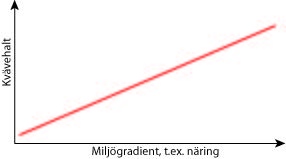
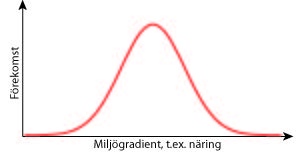
Har man istället t.ex. mark- eller vattenkemi som beskrivningsvariabler följer beskrivningsvariablerna en linjär fördelning (vänstra figuren). Vid analys av data måste man använda sig av rätt typ av metoder som tar hänsyn till att det uppmätta värdet för organismerna eller kemivariablerna i det ena fallet minskar ju mer extrema förhållandena i naturen blir, medan mätvärdet i det andra fallet bara ökar.
